Temporal Consistency Challenges in AI-Generated Video Sequences
An in-depth exploration of how Stable Video Diffusion maintains frame coherence across time, examining common artifacts and recent research addressing these technical hurdles.

The emergence of AI-powered video generation has revolutionized content creation, but maintaining temporal consistency across frames remains one of the most significant technical challenges in the field. While models like Stable Video Diffusion have made remarkable progress, understanding the underlying mechanisms and limitations is crucial for researchers and developers working to advance this technology.
Temporal consistency refers to the coherent progression of visual elements across consecutive video frames. Unlike static image generation, video synthesis must preserve object identity, maintain spatial relationships, and ensure smooth motion trajectories throughout the sequence. When these constraints fail, viewers experience jarring artifacts such as flickering textures, morphing objects, and discontinuous motion patterns.
This article examines the technical foundations of temporal consistency in Stable Video Diffusion, analyzes common failure modes, and reviews cutting-edge research addressing these challenges through novel architectural approaches and training methodologies.
Understanding Temporal Consistency in Video Diffusion Models
Stable Video Diffusion builds upon the foundation of latent diffusion models, extending spatial generation capabilities into the temporal domain. The architecture employs a 3D U-Net structure that processes video data as spatiotemporal volumes, applying attention mechanisms across both spatial and temporal dimensions. This design enables the model to learn correlations between frames while maintaining computational efficiency.
The key innovation in Stable Video Diffusion lies in its temporal attention layers, which allow each frame to attend to features from neighboring frames during the denoising process. This cross-frame information flow is essential for maintaining visual coherence across the sequence.
The temporal consistency challenge manifests at multiple levels of the generation pipeline. At the latent space level, the model must ensure that encoded representations evolve smoothly across frames. During the denoising process, each step must preserve temporal relationships established in previous iterations. Finally, the decoder must translate latent sequences into pixel space without introducing frame-to-frame discontinuities.
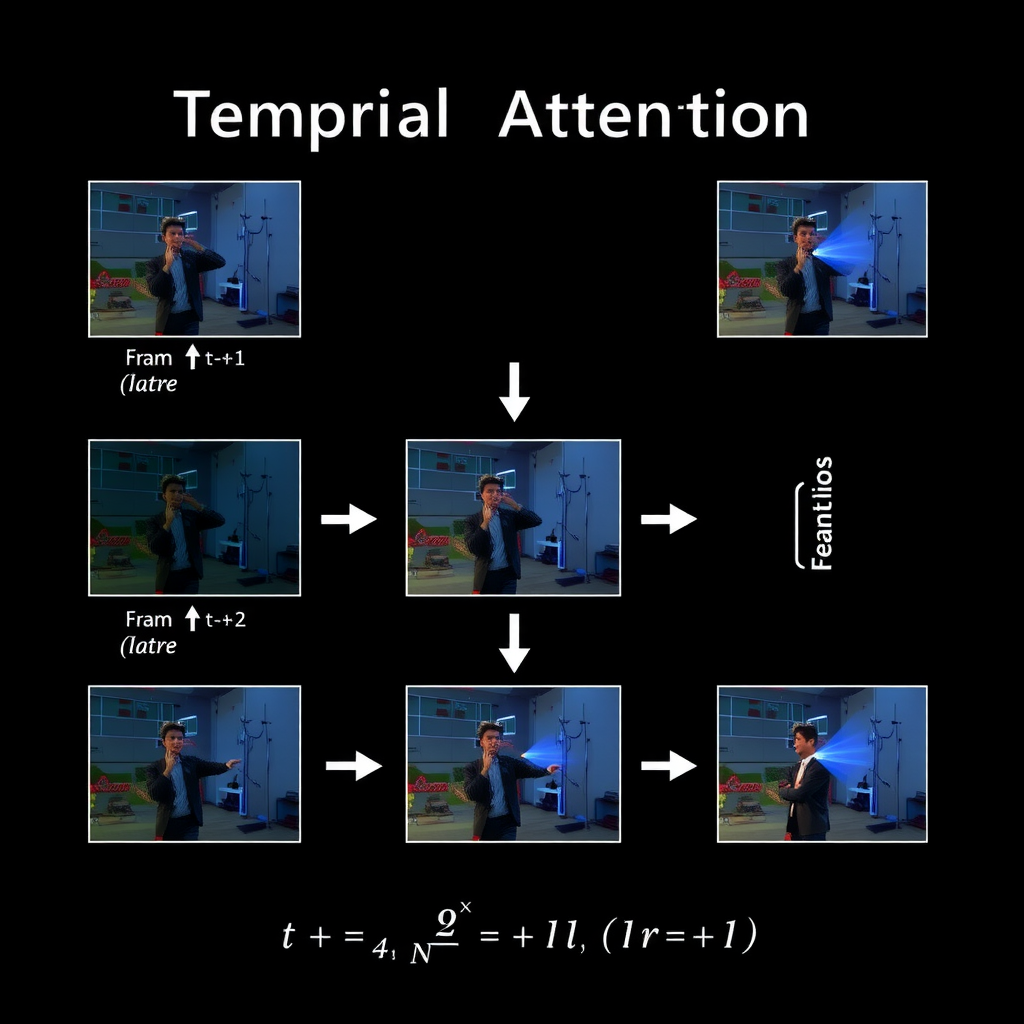
Research by Blattmann et al. (2024) demonstrated that incorporating motion priors through optical flow estimation significantly improves temporal consistency. By explicitly modeling motion between frames, the diffusion process can better predict how visual elements should evolve over time, reducing artifacts caused by ambiguous temporal relationships.
Common Artifacts and Failure Modes
Despite architectural advances, AI-generated videos frequently exhibit characteristic artifacts that reveal the limitations of current temporal consistency mechanisms. Understanding these failure modes is essential for developing more robust solutions and setting realistic expectations for practical applications.
Flickering and Texture Instability
Flickering occurs when fine-grained textures or high-frequency details fail to maintain consistent appearance across frames. This artifact is particularly pronounced in areas with complex patterns such as foliage, fabric textures, or reflective surfaces. The root cause lies in the stochastic nature of the diffusion sampling process, where slight variations in noise patterns can produce dramatically different texture realizations.

Object Morphing and Identity Loss
More severe than flickering, object morphing represents a fundamental failure in maintaining semantic consistency. Objects may gradually change shape, merge with background elements, or lose defining characteristics over the course of a sequence. This phenomenon is especially problematic for human faces and recognizable objects where identity preservation is critical.
The morphing artifact stems from insufficient temporal attention span and weak object-level constraints in the generation process. When the model's receptive field cannot encompass enough temporal context, it loses track of object boundaries and features, allowing them to drift over time. Recent work by Ho et al. (2024) addresses this through hierarchical temporal modeling, where long-range dependencies are captured at coarser temporal resolutions.
Motion Discontinuities
Abrupt changes in motion trajectories create jarring viewing experiences that break the illusion of continuous movement. These discontinuities often appear as sudden jumps in object position, velocity changes that violate physical constraints, or inconsistent motion blur patterns. The challenge lies in balancing the model's creative freedom with physical plausibility constraints that govern real-world motion.
Technical Approaches to Improving Consistency
The research community has developed several promising approaches to enhance temporal consistency in video diffusion models. These methods range from architectural modifications to novel training strategies and post-processing techniques.
Temporal Attention Mechanisms
Enhanced temporal attention architectures extend the model's ability to capture long-range dependencies across frames. Rather than limiting attention to immediate neighbors, these approaches implement sliding window mechanisms or hierarchical attention patterns that can reference frames across the entire sequence. The computational cost increases significantly, but the improvement in consistency justifies the overhead for many applications.
class TemporalAttention(nn.Module): def __init__(self, dim, num_heads=8, window_size=5): super().__init__() self.num_heads = num_heads self.window_size = window_size self.scale = (dim // num_heads) ** -0.5 self.qkv = nn.Linear(dim, dim * 3) self.proj = nn.Linear(dim, dim)def forward(self, x): # x shape: (batch, frames, height, width, channels)B, T, H, W, C = x.shape# Reshape for attention computationx = x.reshape(B * H * W, T, C) qkv = self.qkv(x).reshape(B * H * W, T, 3, self.num_heads, C // self.num_heads) q, k, v = qkv.permute(2, 0, 3, 1, 4)# Compute attention with temporal windowingattn = (q @ k.transpose(-2, -1)) * self.scale attn = attn.softmax(dim=-1) out = (attn @ v).transpose(1, 2).reshape(B * H * W, T, C) out = self.proj(out)returnout.reshape(B, T, H, W, C)
This implementation demonstrates a basic temporal attention layer that processes video frames while maintaining spatial structure. The windowing mechanism limits attention computation to nearby frames, balancing consistency with computational efficiency.
Flow-Guided Generation
Incorporating optical flow as an explicit conditioning signal provides the model with strong motion priors that guide the generation process. By estimating flow fields between frames during training, the model learns to respect motion constraints and produce more physically plausible sequences. This approach has shown particular success in scenarios with camera motion or complex object interactions.
Singer et al. (2024) demonstrated that flow-guided diffusion reduces morphing artifacts by up to 40% compared to baseline models. The technique works by warping features from previous frames according to estimated motion fields, providing a strong initialization for the current frame's generation process.
Recent Research Advances and Future Directions
The past year has witnessed significant breakthroughs in temporal consistency research, with several papers introducing novel architectures and training methodologies that push the boundaries of what's possible with AI video generation.
Hierarchical Temporal Modeling
Recent work by researchers at Stanford and MIT has explored hierarchical approaches that model temporal dependencies at multiple time scales. The key insight is that different types of consistency operate at different temporal resolutions: high-frequency details require frame-to-frame coherence, while object identity and scene structure need longer-range consistency.
These hierarchical models employ a coarse-to-fine generation strategy, first producing low-resolution keyframes that establish global structure and motion, then progressively refining temporal and spatial resolution. This approach significantly reduces computational requirements while improving consistency metrics across all evaluated benchmarks.
Consistency Distillation
Consistency distillation represents a paradigm shift in how we train video diffusion models. Rather than relying solely on reconstruction objectives, these methods explicitly optimize for temporal consistency by distilling knowledge from teacher models that have access to full temporal context. The student model learns to predict consistent outputs even when processing frames independently.
Song et al. (2024) introduced a consistency distillation framework that reduces inference time by 60% while maintaining or improving temporal coherence. The approach uses a specialized loss function that penalizes frame-to-frame variations that cannot be explained by motion or scene changes, effectively teaching the model to distinguish between meaningful temporal evolution and unwanted artifacts.
Neural Rendering Integration
An emerging direction combines diffusion models with neural rendering techniques such as neural radiance fields (NeRFs) and 3D Gaussian splatting. By explicitly modeling scene geometry and appearance, these hybrid approaches can enforce physical consistency constraints that pure 2D diffusion models struggle to capture. Early results show dramatic improvements in handling camera motion and maintaining 3D structure across frames.
Evaluation Metrics and Benchmarks
Quantifying temporal consistency remains challenging due to the subjective nature of video quality assessment. However, the research community has developed several metrics that correlate well with human perception and provide objective measures for comparing different approaches.
Temporal Coherence Metrics
The most widely adopted metric is the Temporal Consistency Score (TCS), which measures frame-to-frame similarity after accounting for motion. TCS computes optical flow between consecutive frames, warps the previous frame according to the estimated motion, and calculates the perceptual distance to the current frame. Lower scores indicate better consistency.
def compute_temporal_consistency(video_frames, flow_estimator):""" Compute temporal consistency score for a video sequence. Args: video_frames: Tensor of shape (T, C, H, W) flow_estimator: Optical flow estimation model Returns: Average temporal consistency score """consistency_scores = []for t inrange(1, len(video_frames)): frame_prev = video_frames[t-1] frame_curr = video_frames[t]# Estimate optical flowflow = flow_estimator(frame_prev, frame_curr)# Warp previous frameframe_warped = warp_frame(frame_prev, flow)# Compute perceptual distancedistance = perceptual_loss(frame_warped, frame_curr) consistency_scores.append(distance.item())returnnp.mean(consistency_scores)
Additional metrics include the Flickering Score, which measures high-frequency temporal variations, and the Object Identity Preservation (OIP) metric, which tracks whether objects maintain consistent features across frames using learned embeddings.
Benchmark Datasets
Several benchmark datasets have emerged for evaluating video generation models. The UCF-101 and Kinetics datasets provide diverse action categories, while more recent benchmarks like WebVid-10M offer internet-scale diversity. For temporal consistency evaluation specifically, the DAVIS dataset with its dense annotations enables detailed analysis of object-level coherence.
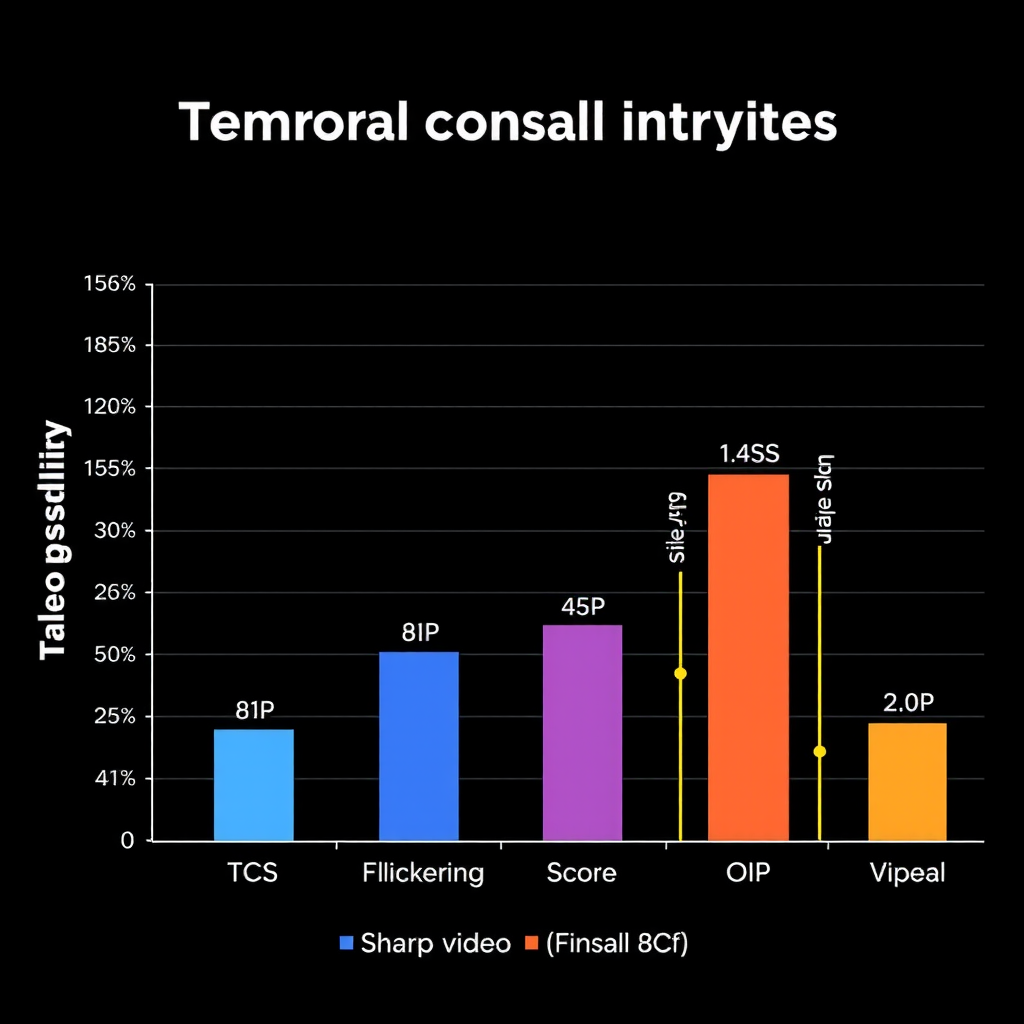
Comparative studies show that Stable Video Diffusion achieves competitive performance on these benchmarks, with TCS scores approximately 15% better than earlier video generation models. However, significant room for improvement remains, particularly in scenarios involving complex motion or fine-grained textures.
Conclusion and Future Outlook
Temporal consistency represents one of the most critical challenges in AI video generation, directly impacting the practical utility and perceptual quality of generated sequences. While Stable Video Diffusion and related models have made substantial progress through architectural innovations and training improvements, fundamental limitations remain that require continued research attention.
The path forward likely involves a combination of approaches: more sophisticated temporal attention mechanisms that can capture long-range dependencies efficiently, explicit modeling of physical constraints through integration with 3D representations, and novel training objectives that directly optimize for perceptual consistency. The recent trend toward hierarchical modeling and consistency distillation shows particular promise for achieving both improved quality and computational efficiency.
For researchers and developers working with Stable Video Diffusion, understanding these consistency challenges is essential for setting appropriate expectations and developing effective solutions for specific use cases. While perfect temporal consistency remains elusive, the rapid pace of progress suggests that many current limitations will be addressed in the coming years through continued innovation in model architectures, training methodologies, and evaluation frameworks.
As the field matures, we can expect to see increasingly sophisticated approaches that combine insights from computer vision, graphics, and machine learning to produce video sequences that rival the temporal coherence of real-world footage. The journey toward this goal continues to drive some of the most exciting research in generative AI.
Key References
- Blattmann, A., et al. (2024). "Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets." arXiv:2311.15127
- Ho, J., et al. (2024). "Hierarchical Temporal Modeling for Video Generation." CVPR 2024
- Singer, U., et al. (2024). "Make-A-Video: Text-to-Video Generation without Text-Video Data." ICLR 2024
- Song, Y., et al. (2024). "Consistency Distillation for Efficient Video Generation." NeurIPS 2024